AI Ajan Değerlendirmesi: Ajanlarınızı Anlamanın ve İyileştirmenin En Güvenilir Yolu
AI ajanları daha gelişmiş, daha yetenekli ve iş dünyasına daha derinlemesine entegre hale geliyor.
Ancak her ekibin karşılaştığı evrensel bir sorun var:
Ajanınız her zaman beklediğiniz gibi yanıt vermiyor - ve nedenini bilmiyorsunuz.
Bazen akıl yürütme değişir, bazen ajan bir kuralı görmezden gelir, bazen araç doğru kullanılmaz ve bazen ince bir talimat yanlış anlaşılır. Kararların nasıl alındığına dair bir görünürlük olmadan, ajanı iyileştirmek tahmin işi gibi hissedilir.
Tam da bu nedenle Agent Değerlendirmelerini oluşturduk - AgentX içinde, ajanınızın aynı sorunun birden fazla çalışmasında nasıl davrandığını test etmenizi, ölçmenizi ve derinlemesine analiz etmenizi sağlayan yeni bir sistem.
İlk kez, ajanınızın karar alma sürecini görebilir, tutarsızlıkları bulabilir ve iyileştirmelerin tam olarak nerede gerektiğini anlayabilirsiniz.
Değerlendirmelerin Önemi
AI modelleri olasılıksaldır.
Aynı komut istemi, bağlam ve kurallarla bile model:
hafifçe farklı akıl yürütme yolları üretebilir
gerekli bir detayı atlayabilir
bir politikayı yanlış yorumlayabilir
bir araç aramasını atlayabilir
beklenen kesin yanıt yerine belirsiz yanıtlar verebilir
bir ekip içinde tutarsız bir şekilde görev dağıtabilir
Dışarıdan sadece nihai yanıtı görürsünüz.
Görmezsiniz:
ajanın talimatlarınızı takip edip etmediğini
doğru araçları kullanıp kullanmadığını
doğru akıl yürütüp yürütmediğini
neden bir yanıtın diğerinden daha zayıf olduğunu
neden bazen doğru, bazen yanlış olduğunu
Değerlendirmeler, yapı, puanlama ve şeffaflık sağlayarak bu sorunu çözer.
Bir Test Nasıl Çalışır
Bir değerlendirme oluşturmak basittir:
0. Değerlendirmek istediğiniz Ajan veya ekibi seçin.
1. Test Sorusu
Bu, doğrulamak istediğiniz gerçek dünya sorusudur.
Bir müşteri sorgusunu veya dahili bir iş akışı talebini simüle eder.
Örnek:
“Uymuyorsa, Son Satış ürününü iade edebilir miyim?”
Bu, değerlendirmenin çekirdeğini oluşturur.
2. Beklenen Sonuçlar (Gerekli)
Bu, yapılandırmanın en önemli parçasıdır.
Burada, yanıtın doğru kabul edilmesi için ajanınızın NE söylemesi veya içermesi gerektiğini tanımlarsınız.
Şunları içerebilir:
anahtar bilgiler
zorunlu ifadeler
gerekli akıl yürütme adımları
uyum kuralları
belirli bir ton veya politika ifadeleri
Örnek:
“Şunu söylemeli: Hayır, Son Satış ürünleri iade edilemez veya değiştirilemez.”
Beklenen Sonuçlar, tüm test çalışmaları için puanlama kriteri haline gelir.
3. Beklenen Yetenekler (İsteğe Bağlı ama Güçlü)
Değerlendirme sistemine, ajanınızın hangi araçları, belgeleri veya bilgi kaynaklarını kullanması gerektiğini söyleyebilirsiniz.
Örneğinizde, şunları seçtiniz:
Documents → store_policy_kb_v1.xlsx
Built-in Functions
Bu şu anlama gelir:
Ajan, politika KB'den bilgi almalıdır.
Eğer KB'yi doğru kullanmazsa, değerlendirme bunu yakalayacaktır.
Bu, şunlar için mükemmeldir:
politika ajanları
müşteri hizmetleri ajanları
uyum iş akışları
finans modelleme
veri destekli akıl yürütme
4. Değerlendirme Ayarları
Bu bölüm, değerlendirmenizin ne kadar titiz ve ne kadar derin olması gerektiğini tanımlar.
Test Çalışma Sayısı
Aynı soru birden fazla kez yürütülür (Önerilen: 5 çalışma).
Neden?
Çünkü AI modelleri deterministik değildir. Birden fazla çalışma, şunları kontrol etmenizi sağlar:
tutarlılık
kararlılık
akıl yürütme güvenilirliği
ajanın her seferinde aynı süreci takip edip etmediği
Eğer ajan bir iyi yanıt ve dört başarısızlık üretirse, bunu anında görürsünüz.
Kabul Kriterleri
Bu kaydırıcı, yanıtın Beklenen Sonuçlarınızla ne kadar sıkı eşleşmesi gerektiğini tanımlar.
Şu noktalar arasında bir seçim yapıyorsunuz:
Esnek → ajan beklentilerinizden sapabilir; yanıtın mükemmel olması gerekmez.
Kesin → yanıt beklentilerinizi çok yakından takip etmeli, neredeyse hiç varyasyon olmamalıdır.
Bu, yanıtın değerlendirmeyi geçmesi için ne kadar kesin olması gerektiğini kontrol eder.
Reddetme Kriterleri (İsteğe Bağlı)
Otomatik başarısızlık kuralları.
Örnekler:
“Yanıt rakiplerden bahsetmemelidir.”
“Politika yasakladığında iade teklif etmeyin.”
“Yanıt, kullanıcıdan kişisel bilgi istememelidir.”
Bunlar katı kısıtlamalardır.
Değerlendirme Kriterleri (İsteğe Bağlı)
Genellikle kalite veya ton için kullanılan ek puanlama rehberliği.
Örnekler:
“Yanıt dostça ve profesyonel olmalıdır.”
“Yanıt sadece evet/hayır değil, kısa bir açıklama içermelidir.”
“Varsayımlardan önce KB gerçeklerini kullanın.”
Bunlar katı gereklilikler değildir ancak AI'nın ajanı nasıl puanladığını şekillendirmeye yardımcı olur.
5. Değerlendirme Oluştur
Yapılandırıldıktan sonra, Değerlendirme Oluştur düğmesine tıklamak süreci başlatır:
soru birkaç kez çalıştırılır
her yanıt puanlanır
detaylı bir analiz oluşturulur
görev dağıtımı ve araç kullanımı incelenir
tutarsızlıklar ortaya çıkarılır
Ve eksiksiz bir performans raporu geri alırsınız.
Değerlendirmeyi Çalıştırdıktan Sonra Ne Elde Edersiniz
Birkaç çalışmadan sonra, AgentX iki katmanlı bir çıktı sağlar:
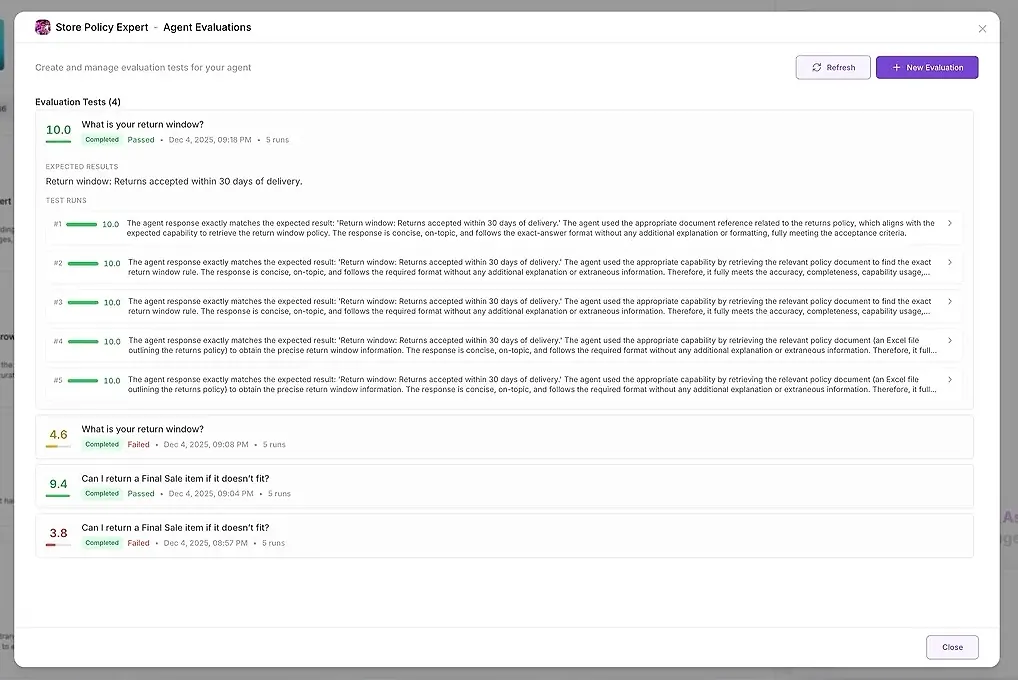
1. Test Sonuçları
Her çalışma için şunları görürsünüz:
sayısal bir puan
beklentilerinize ne kadar iyi uyduğunun bir özeti
tam yanıt
hangi araçların kullanıldığı
hangi ajanların katıldığı
ajanın nerede başarısız olduğu veya saptığı
Bu, yanıtları yan yana karşılaştırmanıza ve kalıpları tanımlamanıza olanak tanır.
2. Derin AI Analizi
Gerçek sihir burada gerçekleşir.
AgentX tüm çalışmaları otomatik olarak analiz eder ve birden fazla kategoriye yayılmış yapılandırılmış bir rapor oluşturur:
• Talimat Uygunluğu
Ajan kurallarınızı takip etti mi?
• Yanıt Kalıpları
Yanıtlar ne kadar benzer veya farklıydı?
Aykırı değerler var mı?
• Akıl Yürütme Analizi
Akıl yürütme adımları doğru, eksiksiz ve beklentilerle uyumlu muydu?
• Araç Kullanımı
Ajan doğru aracı kullandı mı?
Bir arama atladı mı?
Doğrulanmış gerçekler yerine varsayımlara mı dayandı?
• Öneriler
Ajanınızı iyileştirmek için somut, eyleme geçirilebilir öneriler.
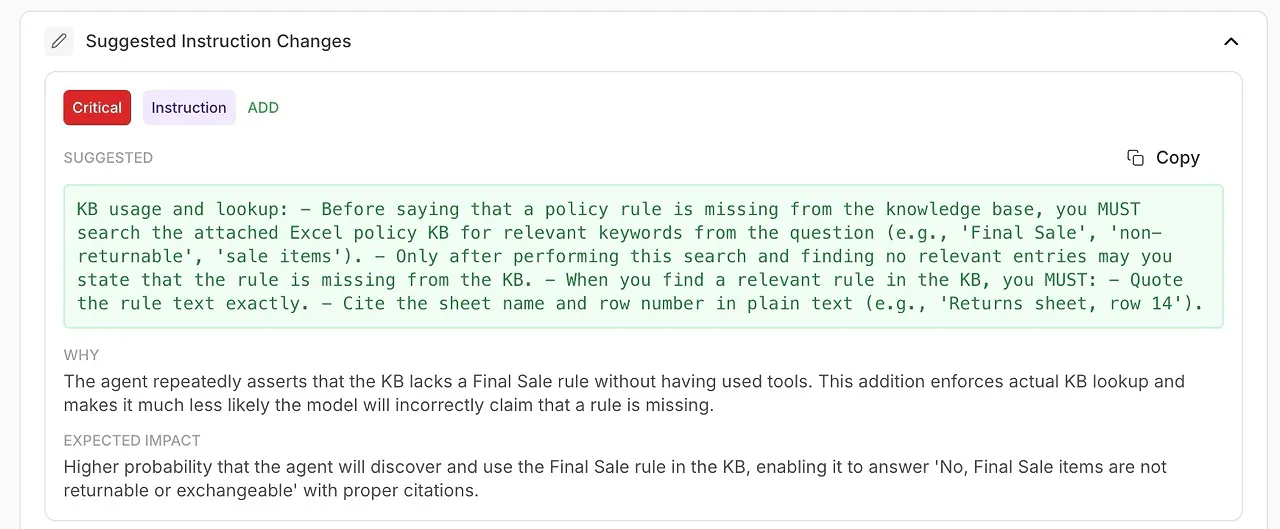
• Önerilen Talimat Değişiklikleri
Sistem isteminiz veya ajan yapılandırmanız için otomatik olarak oluşturulan iyileştirmeler.
• Genel Değerlendirme
Güçlü yönlerin, zayıf yönlerin ve güven seviyesinin bir özeti.
Bu, hata ayıklamayı bir tahmin oyunundan bilimsel, tekrarlanabilir bir sürece dönüştürür.
Bu Özelliğin Sağladıkları
Değerlendirmeler, ajanlarınızın nasıl çalıştığına dair yeni bir şeffaflık ve güvenilirlik seviyesi getirir. Bir yanıtın neden yanlış veya tutarsız olduğunu tahmin etmek yerine, artık davranışı anlamak, sorunları teşhis etmek ve performansı sürekli olarak iyileştirmek için yapılandırılmış, ölçülebilir bir yolunuz var.
İşte mümkün olanlar:
🔍 Ajanınızı müşterilere sunmadan önce doğrulayın
Bir ajanı üretime göndermeden önce, kurallarınızı, bilgi tabanınızı ve istenen tonu tam olarak anlayıp anlamadığını ortaya çıkaran gerçekçi testler yapabilirsiniz. Dağıtımdan sonra sürpriz yok — kullanıcıların tam olarak ne deneyimleyeceğini biliyorsunuz.
🤖 Tüm ajan ekibinizi ve görev dağıtım mantığınızı test edin
Çok ajanlı kurulumlar için, Değerlendirmeler yöneticinizin görevleri nasıl dağıttığını, hangi alt ajanların katıldığını ve beklenen iş akışını takip edip etmediklerini gösterir. Hızla tespit edebilirsiniz:
gereksiz görev dağıtımları
eksik görev dağıtımları
çelişkili ajanlar
yanlış rol davranışı
Bu, AI iş gücünüz içinde güvenilir ekip çalışması için gereklidir.
📚 Bilgi tabanınızdaki zayıf noktaları tespit edin
Bir değerlendirme belirli bir konuda tekrarlanan başarısızlıklar gösteriyorsa, sorun ajan değil — eksik veya belirsiz içerik. Değerlendirmeler, körü körüne daha fazla malzeme eklemek yerine, bilgi tabanınızı hedefli, veri odaklı bir şekilde rafine etmenize yardımcı olur.
🚨 Halüsinasyonları ve tutarsızlıkları erken yakalayın
Her soru birden fazla kez test edildiğinden, Değerlendirmeler şu gibi ince sorunları ortaya çıkarır:
yanıtların öngörülemez bir şekilde değişmesi
akıl yürütmenin kayması
araç kullanımının yerini tahminlerin alması
çalışmalar arasında çelişkiler
Bunlar, manuel olarak bir veya iki kez test ederek asla tanımlayamayacağınız sorunlardır.
🧠 AI tarafından üretilen iyileştirmelerle sistem talimatlarını rafine edin
Analiz sadece neyin yanlış gittiğini göstermez — nasıl düzelteceğinizi söyler.
Modelin kendi tanılarına dayanan eyleme geçirilebilir öneriler alırsınız:
iyileştirilmiş ifade
daha sıkı kurallar
zorunlu araç kullanımı
daha net görev dağıtım politikaları
daha kesin ton ve yapı
Bu, iş akışınıza doğrudan entegre edilmiş otomatik istem mühendisliğidir.
📈 Ajanınızı güncellediğinizde ilerlemeyi ölçün
Ne zaman:
bir sistem istemi
bir bilgi tabanı girişi
bir araç
bir görev dağıtım kuralı
bir akıl yürütme politikası
...değiştirdiğinizde, aynı değerlendirmeyi yeniden çalıştırabilir ve puanları karşılaştırabilirsiniz. Güncellemenizin performansı nasıl etkilediğini — olumlu veya olumsuz olarak — tam olarak görürsünüz.
Değerlendirmeler, sürekli iyileştirme döngünüz haline gelir.
✔ Kuruluşunuz genelinde yüksek kaliteli, uyumlu yanıtları uygulayın
Destek, finansal analiz, sağlık senaryoları veya yasal hassas içeriklerle uğraşırken, Değerlendirmeler şunları sağlamanıza olanak tanır:
politikaların takip edilmesi
ton yönergelerinin saygı görmesi
tehlikeli boşlukların işaretlenmesi
yanlış akıl yürütmenin ortaya çıkarılması
uyum standartlarının karşılanması
Bu, özellikle kurumsal ve müşteri odaklı AI için kritik öneme sahiptir.
Kullanım ve Maliyetler
Agent Değerlendirmeleri, AgentX'in geri kalanıyla aynı kredi modelini kullanır. Her test çalışması, normal bir ajan mesajı gibi kredi tüketir - ekstra ücret yok, gizli fiyatlandırma yok. Harcadığınız şeyi her zaman tam olarak bilirsiniz, çünkü Değerlendirmeler mevcut plan limitlerinizi ve kredi bakiyenizi takip eder.
AI için Kalite Kontrol Katmanınız
Geleneksel yazılımda, QA güvenilirliği sağlar.
AgentX'te, Değerlendirmeler ajanlarınız için QA'dır.
“İyi”nin nasıl göründüğünü tanımlarsınız.
AgentX, ajanlarınızın bunu sürekli olarak sunup sunamayacağını kontrol eder — ve yapmadıklarında tam olarak neyi iyileştireceğinizi gösterir.
Değerlendirmeler, AI'yı bir kara kutudan şeffaf, ölçülebilir, iyileştirilebilir bir sisteme dönüştürür.