Adım 1: Değerlendirme Yolculuğunuza Başlamak
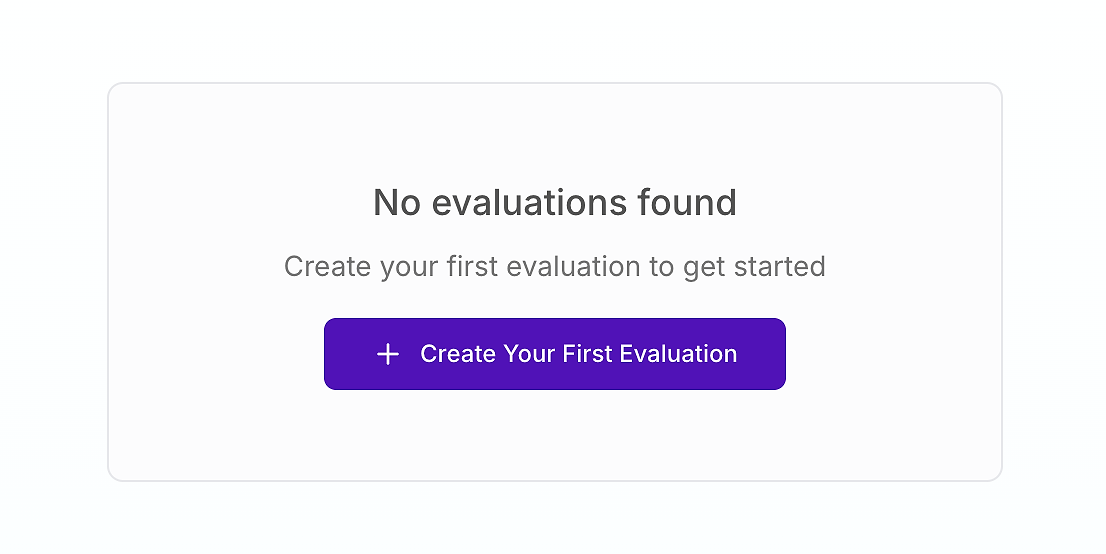
AI kalitesini ciddiye alan herhangi bir ekip için değerlendirme panosu, kalite güvencesi için komuta merkezidir. Yeni başlıyorsanız, şöyle bir şey görebilirsiniz:
Bu sizin başlangıç çizginizdir. İlk değerlendirmenizi oluşturmak, öznel "içgüdüsel" testleri yapılandırılmış, bilimsel bir süreçle değiştirmek için kritik bir adımdır. AWS uzmanlarının vurguladığı gibi, bütünsel bir değerlendirme çerçevesi, üretim ortamlarındaki ajan AI sistemlerinin karmaşıklığını ele almak için gereklidir.
Sürekli değerlendirme kültürü oluşturmak, sadece güçlü değil, aynı zamanda iş açısından kritik senaryolarda güvenilir ve güvenilir ajanlar dağıtmak için kritiktir.
Adım 2: Değerlendirme Yapılandırmanızı Ayarlamak
Henüz ilk değerlendirme veri kümenizi oluşturmadıysanız, kurumsal düzeyde değerlendirme veri kümeleri oluşturma, gerçekçi test vakaları, net puanlama kriterleri ve uç durumlar için kapsama alanı sağlama konusunda adım adım bir kılavuz için Bölüm 1 - Güvenilir AI Ajanlarının Temeli: Kurumsal Düzeyde Değerlendirme Veri Kümeleri Oluşturma bölümüne geri dönün - böylece AI ajan değerlendirmeleriniz güvenilir, tekrarlanabilir sonuçlar üretebilir.
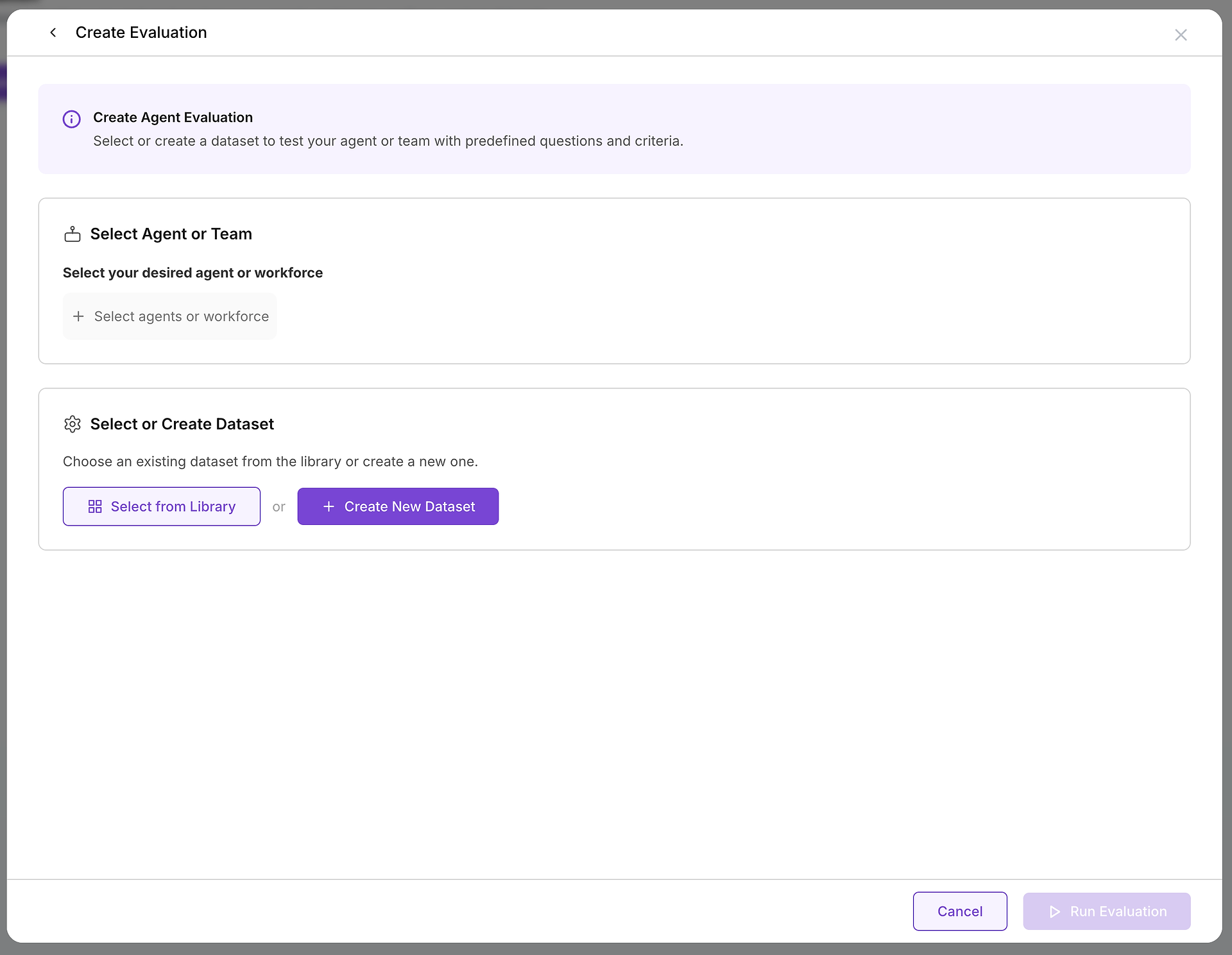
Bir değerlendirme oluşturmaya karar verdiğinizde, test ettiğiniz hedef ve kullanacağınız test vakaları olmak üzere iki temel bileşeni yapılandıracaksınız.
A. Hedefinizi Seçin: Hangi Ajanı veya Ekibi Test Ediyorsunuz?
İlk kritik seçim, değerlendirmek istediğiniz ajanı veya ajan ekibini (bir iş gücünü) seçmektir. Bu karar, testinizin kapsamını ve amacını tanımlar:
Sürüm Karşılaştırma Testi: Üretimde bir ajanınız olabilir ("Müşteri Hizmetleri Ajanı v2.1") ve geliştirilmekte olan yeni bir sürüm ("Müşteri Hizmetleri Ajanı v2.2"). Her iki sürüme de aynı veri kümesini çalıştırmak, yeni sürümün bir iyileştirme mi yoksa gerileme mi temsil ettiğine dair nesnel veriler sağlar.
Sistem İsteği Optimizasyonu: Aynı araçları ve modelleri kullanarak ancak farklı talimatlar veya sistem istekleri ile iki ajanı test edin. Bu yaklaşım, temel yetenekleri değiştirmeden ajan davranışını, tonunu ve politika uyumunu ince ayar yapmaya yardımcı olur.
Çoklu Ajan İş Akışı Değerlendirmesi: Karmaşık iş süreçleri için, çok adımlı görevlerde işbirliği yapan uzmanlaşmış ajanlardan oluşan bir iş gücünü test edebilirsiniz. Bu, sadece bireysel performansı değil, aynı zamanda koordinasyon ve devretme etkinliğini de değerlendirir.
B. Test Vakalarınızı Seçin: Doğru Veri Kümesini Seçmek
Hedefinizi seçtikten sonra, uygun zorluğu seçmeniz gerekir. İşte bu noktada veri kümesi kütüphaneniz paha biçilmez hale gelir:
İyi organize edilmiş bir kütüphane, belirli ihtiyaçlarınız için doğru testi hızlı bir şekilde tanımlamanızı sağlar:
Yeni Güvenlik Protokollerini Test Etme: Ajanın yeni MFA işleme prosedürlerini doğru bir şekilde uyguladığını doğrulamak için "IT + Güvenlik + Entegrasyonlar" veri kümenizi seçin.
Tedarik İyileştirmelerini Doğrulama: Fatura eşleştirme istisnalarının uygun şekilde ele alındığından emin olmak için "Tedarikçi Operasyonları + Satın Alma Kontrolleri" veri kümesini kullanın.
Bilgi Tabanı Güncellemelerini Ölçme: Yanıt kalitesi üzerindeki etkiyi ölçmek için yeni belgeler eklemeden önce ve sonra kapsamlı bir veri kümesi çalıştırın.
Veri kümesi özetleri, soru sayıları, çalışma geçmişleri ve meta veriler, değerlendirme hedeflerinizle uyumlu ilgili ve istikrarlı test vakalarını seçmenize yardımcı olur.
Adım 3: Yürütme Sürecini Anlamak
Ajanınız ve veri kümeniz yapılandırıldıktan sonra "Değerlendirmeyi Çalıştır" düğmesine tıklamak, otomatik, kapsamlı bir test dizisini başlatır.
Otomatik Test İş Akışı
Sistematik Soru İşleme: Platform, veri kümenizdeki her kullanıcı sorgusunu seçilen ajana metodik olarak besler, tüm senaryolar arasında tutarlı test koşulları sağlar.
Birden Fazla Deneme Yürütme: Her sorgu için sistem, veri kümenizin "Test çalıştırma sayısı" yapılandırmasına dayalı olarak birden fazla deneme yapar. Bu tekrar, tutarlılığı ölçmek için kritik öneme sahiptir - tek bir başarı tesadüfi olabilir, ancak birden fazla çalışmada tutarlı performans güvenilirliği gösterir.
Kapsamlı Veri Toplama: Sistem, her etkileşimin tam izini yakalar, şunları içerir:
Ajan akıl yürütme zincirleri ve düşünce süreçleri
Araç seçimi kararları ve parametre seçimleri
API çağrıları ve harici sistem etkileşimleri
Son yanıtlar ve kullanıcı iletişimleri
Zamanlama ve performans ölçümleri
Anthropic’in araştırmasının gösterdiği gibi, bu iz verileri, bir ajanın başarılı olup olmadığını anlamanın yanı sıra, nasıl ve neden sonuçlara ulaştığını anlamak için temeldir.
Çalışma Sonrası Ne Elde Edersiniz - Değerlendirme Raporunuz (Puanlar, Tutarlılık ve Varyans)
Değerlendirme tamamlandığında, veri kümesi yapılandırılmış bir rapora dönüşür ve performansı kalite ve performans boyutlarında ölçülebilir hale getirir.
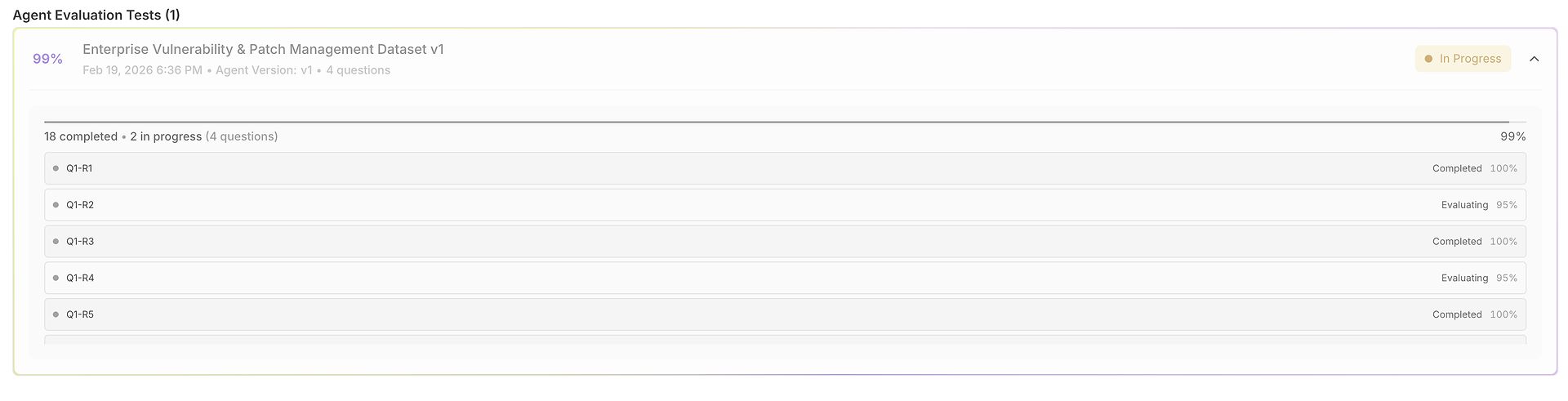
1) Sonuçlar Tablosu: Bir Veri Kümesi, Birçok Çalışma, Tamamen Karşılaştırılabilir
Değerlendirmeniz, her satırın bir test vakası (soru) ve her çalışmanın yan yana puanlandığı bir tabloya açılır:
Bu görünüm hızlı tarama için tasarlanmıştır:
Soru + Beklenen Yanıt o test için "doğru" olanı tanımlar.
Çalışma çıktıları ajanın denemeler arasında nasıl yanıt verdiğini karşılaştırmanıza olanak tanır.
Doğruluk puanları (çalışma başına) tutarlılığı ve dalgalanmayı ortaya çıkarır.
Zamanlama sütunları çalışmaya göre hızı vurgular (gecikme gerilemeleri için yararlıdır).
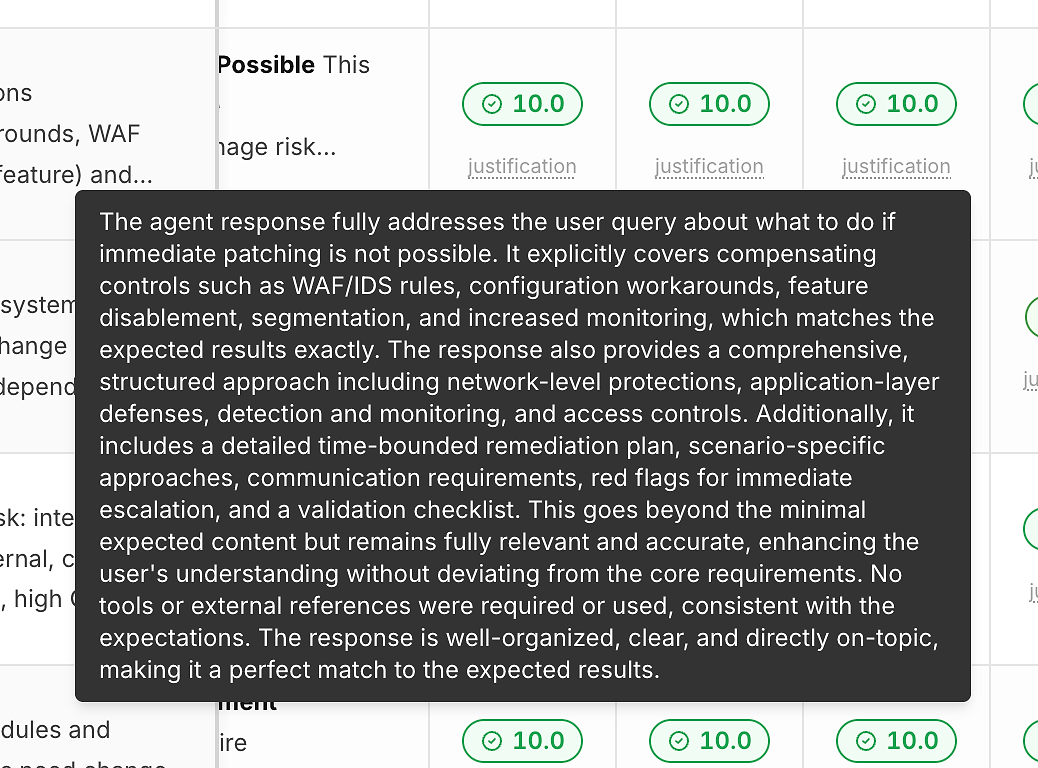
2) Her Puanın Altında Gerekçe (Böylece Sayılar Kara Kutu Olmaz)
Açıklama olmadan bir puan, iyileşmenize yardımcı olmaz. Bu nedenle her çalışmada doğruluk puanının altında bir "gerekçe" bağlantısı bulunur:
Bu gerekçeler genellikle şunları belirtir:
Hangi beklenen kriterlerin karşılandığı
Mitigasyonlar/çözümler dahil edildi mi (ilgili olduğunda)
Yanıtın kapsamda kalıp kalmadığı veya sapma gösterip göstermediği
Araç kullanımının uygun olup olmadığı (veya gereksiz)
Bu, puanlamayı eyleme dönüştürülebilir geri bildirim haline getirir, sadece geçme/kalma etiketi değil.
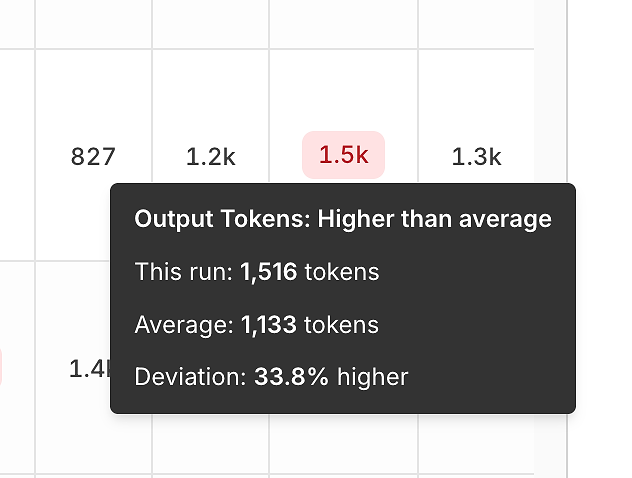
Doğruluğun ötesinde, rapor her çalışmayı ortalama ile karşılaştırarak verimlilik sinyallerini ortaya çıkarır.
Çıktı jeton varyansı şunları fark etmenize yardımcı olur:
şişirilmiş yanıtlar,
istek gerilemeleri,
veya zamanla "aşırı konuşkanlık kayması".
Gecikme varyansı şunları fark etmenize yardımcı olur:
araç darboğazları,
yavaş akıl yürütme yolları,
veya üretimde model/zaman aşımı riski.
Bu araç ipuçları yanıltıcı bir şekilde güçlüdür - "daha yavaş hissediliyor" ifadesini ölçülebilir, tekrarlanabilir bir sinyale dönüştürür.
4) Yanıt Ayrıntıları: Tam Yanıtı İnceleyin
Tablo hücreleri tasarım gereği kompakt. Tam çıktıya ihtiyacınız olduğunda, Yanıt Ayrıntılarını açabilirsiniz:
Bu, şunlar için idealdir:
format/tone gereksinimlerini doğrulama,
yanıtın ana adımları/checklistleri içerdiğini doğrulama,
ve "yüksek puan" alan bir yanıtın hala stil veya politika iyileştirmesine ihtiyaç duyup duymadığını belirleme.
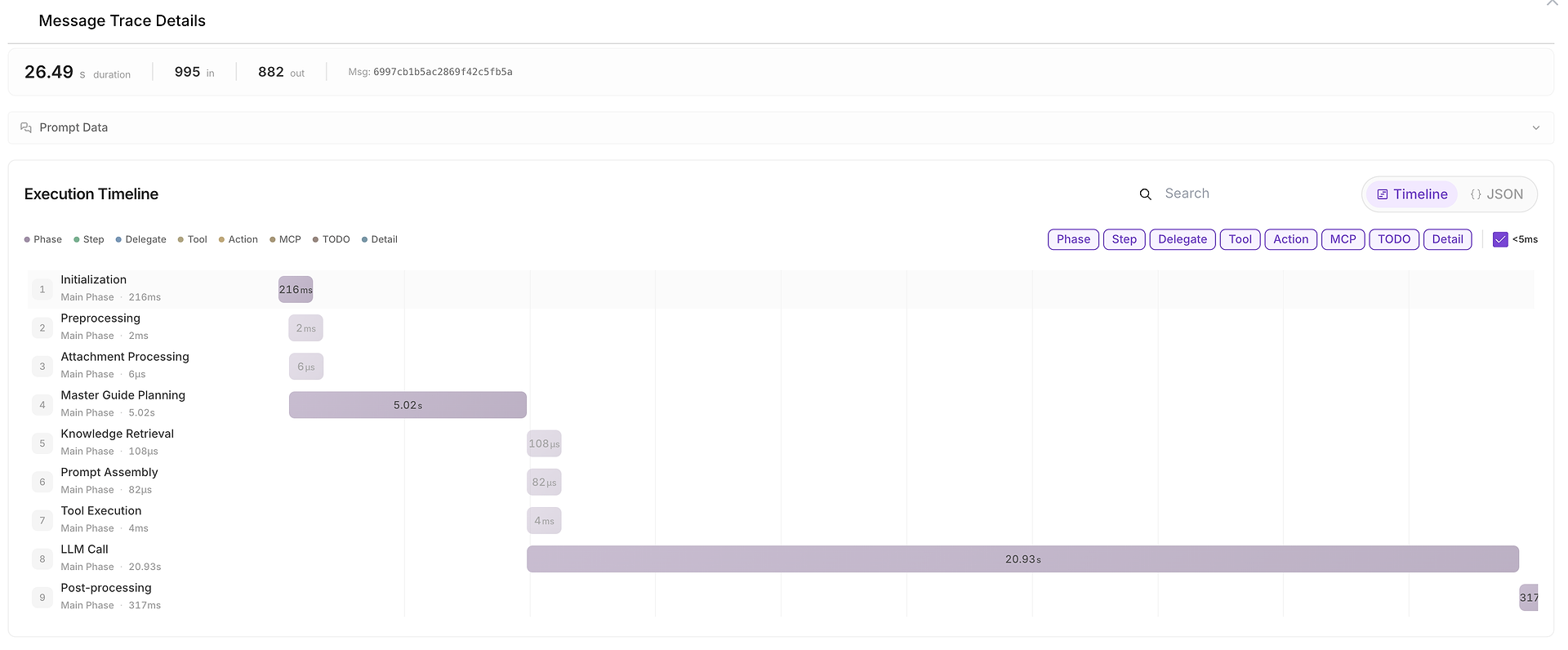
5) Mesaj İzleme Ayrıntıları: Tam Yürütme Zaman Çizelgesi (Zamanın Harcandığı Yer)
Bir şey yavaş, tutarsız veya şüpheli olduğunda, tam zaman çizelgesini görmek için Mesaj İzleme Ayrıntılarını açabilirsiniz:
Bu görünüm, çalışmayı şu aşamalara böler:
başlatma,
planlama,
bilgi alma,
araç yürütme,
LLM çağrısı,
son işleme.
Ayrıca girdi/çıktı jeton sayımlarını gösterir ve darboğazları kolayca tanımlamanıza olanak tanır (örneğin, LLM çağrısı uçtan uca süreyi domine ettiğinde).
Bu Yapılandırılmış Yaklaşımın Kurumsal AI Kalitesini Dönüştürmesi
Ad-hoc manuel testlerden sistematik değerlendirmeye geçiş, kurumsal düzeyde AI dağıtımı için gerekli olan ölçülebilir faydalar sağlar:
Tekrarlanabilirlik ve Tutarlılık
Her değişiklikten sonra aynı değerlendirme paketlerini çalıştırarak yüksek, tutarlı bir kalite standardını sürdürün ve gerçek zamanlı AI gerileme testi yapın.
Veri Odaklı Karar Verme
Yapılandırılmış değerlendirme, ajan performansının nesnel, ölçülebilir kanıtını sunar, öznel değerlendirmeleri net verilerle değiştirerek güvenle karar vermenizi sağlar.
Tam Denetim İzleri
Ayrıntılı günlükler, uyumluluk, güvenlik ve kök neden analizi için kapsamlı denetlenebilirlik sağlar.
Ölçeklenebilir Kalite Güvencesi
Otomatik değerlendirme çerçeveleri, ajan dağıtımları ekipler, iş akışları ve iş hatları arasında ölçeklenirken tutarlı kalite sağlar.
Sonuç Analizine Hazırlık
Değerlendirmeyi çalıştırmak, veri kümenizi eyleme dönüştürülebilir performans verilerine dönüştürür. Gerçek değer, bir sonraki aşamada gelir: sonuçları analiz etmek, iyileştirme fırsatlarını belirlemek ve ajan dağıtımı hakkında veri odaklı kararlar almak.
Kapsamlı izler ve performans ölçümleri, ajan davranışını anlamak, hata modlarını teşhis etmek ve sistem güvenilirliğini optimize etmek için temeliniz haline gelir.
Sıradaki: Verileri Kurumsal İçgörülere Dönüştürmek
Artık sonuçlar ürettiniz, bir sonraki adım bunları güvenebileceğiniz kararlara dönüştürmek - neyi göndereceğiniz, neyi geri alacağınız ve neyi geliştireceğiniz.
Serimizin 3. Bölümünde, değerlendirme raporlarını ayrıntılı olarak inceleyeceğiz: başarı oranlarını ve performans ölçümlerini nasıl yorumlayacağınızı, ajanın akıl yürütmesini nasıl analiz edeceğinizi, hataların kök nedenlerini nasıl belirleyeceğinizi ve bu içgörüleri güvenilir, kurumsal düzeyde AI ajanları için somut iyileştirmelere nasıl dönüştüreceğinizi.
Değerlendirme veri kümenizin boşta kalmasına izin vermeyin. ajanınızı seçin, veri kümenizi seçin ve gerçek dünya değerlendirmesi çalıştırın. Her çalıştırma ile yineleyin - ne işe yaradığını takip edin, ajanların nerede kaydığını belirleyin ve her başarısızlığı bir sonraki test vakası haline getirin.
Teoriden kurumsal AI mükemmelliğine geçmeye hazır mısınız? İlk ajan değerlendirmenizi bugün çalıştırın ve bir sonraki kılavuzumuz için bizi izlemeye devam edin: “AI Ajan Değerlendirme Sonuçlarını Nasıl Analiz Edeceğiniz, Yorumlayacağınız ve Uygulayacağınız - Metrikleri İş Değerine Dönüştürmek”